What Cloud Adoption Really Means in 2025
Beyond “lift-and-shift” 🚚☁️
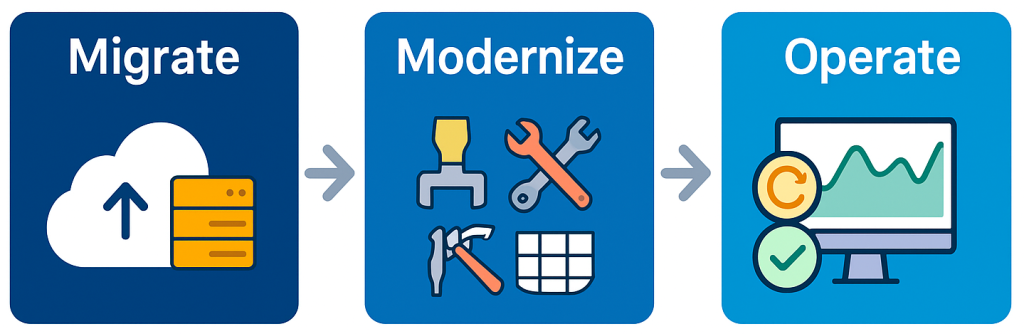
Cloud adoption is a journey:
- Migrate legacy apps to exit data centers and stabilize costs.
- Modernize with managed databases, serverless, and event-driven designs.
- Operate differently using IaC, SRE, FinOps, and platform engineering.
Shared responsibility, clarified 🔐
Providers secure the infrastructure. You secure data, identities, and configuration. Leaders codify guardrails (org policies, templates) so security is built-in, not bolted on.
The Core Business Drivers (Why Leaders Say “Yes”) 🚀
Time-to-market & agility
Minutes to provision environments, safe rollbacks, and faster feedback loops. The outcome: more releases and shorter idea-to-prod time.
Elastic scale (no capacity guessing)
Autoscaling absorbs holiday spikes, launches, and AI inference bursts—without overbuying hardware.
Global reach & performance 🌍
Regions, zones, and CDNs place apps near users and satisfy residency requirements.
Reliability & resilience by design 🛡️
Multi-AZ, automated failover, backups, and SLOs reduce downtime and speed recovery.
Security posture improvements
Centralized identity, KMS, private endpoints, WAF, and continuous posture checks tighten defenses and simplify audits.
AI & data readiness 🤖
Lakehouse + streaming + managed ML/GPU options let teams ship personalization, forecasting, and copilots quickly.
Cost flexibility & visibility 💸
Shift CAPEX→OPEX, tag resources, set budgets/alerts, and apply FinOps so you pay for what you use—and stop paying for what you don’t.
Developer productivity
Internal Developer Platforms (golden paths, templates) remove friction so engineers ship features instead of tickets.

Technology Enablers Powering Adoption 🧩
Managed services as default
DBaaS, caches, queues, search, and observability replace undifferentiated heavy lifting with SLA-backed reliability.
Serverless, where it fits ⚡
Functions, serverless containers, and serverless databases reduce idle cost and ops toil—great for spiky or event-driven work.
Containers & Kubernetes (with restraint) 📦
Managed K8s is common; many teams go higher-level (Cloud Run/App Service/Container Apps) to avoid control-plane overhead.
Data platforms for batch and streaming
Object storage + open table formats + SQL engines unify BI and ML; CDC and streams unlock near-real-time personalization.

IaC, GitOps, and policy-as-code
Terraform/Pulumi + CI/CD + OPA/Config rules make infrastructure reviewable pull requests with guardrails.
Identity-first security
Short-lived credentials, workload identity, secrets managers, and private service endpoints keep blast radius small.
Observability & SRE 🔭
Unified logs/metrics/traces with SLOs and error budgets tie reliability to user outcomes (not just CPU graphs).
Adoption Patterns by Company Size & Sector 🧭
Startups & digital natives
Pattern: serverless-first, one primary cloud, heavy CI/CD.
Risk: cost spikes without tagging/budgets.
Scale-ups
Pattern: managed K8s, lakehouse, multi-region DR, small platform team.
Risk: platform sprawl, duplicated pipelines.
Large enterprises
Pattern: hybrid, landing zones, account factories, centralized guardrails.
Risk: “migrate without modernizing” + slow governance.
Regulated industries
Pattern: sovereignty controls, encryption everywhere, private connectivity, detailed audit trails.
Risk: velocity dips if policies aren’t templatized.
Media, retail, gaming
Pattern: edge + CDN, event streaming, real-time personalization.
Risk: analytics cost runaway, fragmented data models.
Migration & Modernization: Picking the Right “R” 🔧
The common options
- Rehost — fastest exit, least benefit.
- Replatform — managed equivalents (DBaaS, cache, queue).
- Refactor — services, events, serverless; highest payoff, most effort.
- Repurchase — replace with SaaS.
- Retain/Retire — keep or decommission.
Decision cues
- Change rate & customer impact (higher → refactor/replatform).
- Technical debt & brittleness (higher → modernize).
- Data gravity & integrations (may constrain choices).
- Regulatory constraints (residency/encryption).
- Team skills & runway (sequence accordingly).
Cloud Operating Model: How Winning Teams Organize 🏗️
CCoE → Platform Engineering
A small group ships self-service (templates, starter repos, network/IAM baselines, CI/CD) so product teams move fast without tickets.
Landing zone essentials (Day-0 checklist) ✅
- Account/project structure (prod vs non-prod)
- SSO + least-privilege roles + break-glass
- Hub-and-spoke network, private endpoints, egress control
- Org policies, KMS, secrets manager
- Logs/metrics/traces to dashboards; SLOs defined
- FinOps tagging, budgets, alerts, commitments strategy
- IaC repos, CI/CD gates, drift detection
Risks & Practical Mitigations ⚠️
Cost sprawl
Budgets, alerts, tags/labels, showback/chargeback, rightsizing, commitments, quarterly savings reviews.
Vendor lock-in
Use open data formats and IaC; accept managed features where ROI is clear.
Skills gap & change fatigue
Enablement guilds, office hours, pairings, internal demos; make paved roads the easy path.
Governance bottlenecks
Shift approvals to policy-as-code; humans handle exceptions, not every change.
Misconfigurations
Default-deny, pre-approved templates, posture management, and red/chaos-days focused on identity and data paths.
“Repatriation” headlines
Sometimes rational for narrow, stable, ultra-scale workloads. For most, velocity + resilience + reach outweigh raw unit costs—if you modernize and manage spend.
2025 Deep Dives: What’s Actually Changing
AI/GPU strategies 🤖
- Build vs. buy: Use managed training/inference where possible (fewer ops, faster iteration). Self-managed GPUs make sense for steady, high-utilization workloads or custom kernels.
- Right-size the stack: Not every model needs top-tier GPUs—mix CPU, low-cost accelerators, and autoscaled inference endpoints.
- Burst vs. baseline: Commit for baseline capacity; burst with spot/preemptible for experiments. Use queues and concurrency caps to avoid surprise bills.
- Data path first: Tighten feature pipelines (CDC → lakehouse → feature store) before you upscale models; bad data is the top failure mode.
Serverless at scale ⚡
- When it shines: event-driven backends, APIs with unpredictable load, automation jobs, ingestion/ETL edges.
- Gotchas: cold starts (mitigate with provisioned concurrency/CPU boost), per-request limits, noisy neighbor effects, and observability gaps—add tracing early.
- Patterns: Pub/Sub + Functions, Workflows/Step Functions for sagas, serverless containers for heavier deps.
Internal Developer Platforms (IDPs) 🧑💻
- What they are: curated golden paths: service templates, infra modules, secure networking defaults, and paved CI/CD.
- Why they matter: reduce variance, improve compliance-by-default, speed onboarding, and make cost/security visible at deploy time.
- Measure: template adoption %, lead time reduction, tickets avoided.
Lakehouse vs. data mesh 📊
- Lakehouse: unify batch/stream over open table formats; ideal baseline for BI + ML in one platform.
- Mesh: push ownership to domains with shared contracts; great for large orgs with many data producers.
- Hybrid reality: start lakehouse; adopt mesh contracts (schemas, SLAs) where cross-team ownership is real.
Identity-first security 🔐
- Defaults: SSO, short-lived creds, workload identity, JIT/JEA admin, secrets manager, private endpoints.
- Shift-left: policy-as-code, image signing, SBOM checks in CI, drift detection in CD.
- Posture mgmt: continuous checks for misconfig (public buckets, wildcards in IAM, open egress).
Sustainability ♻️
- Quick wins: rightsizing, autoscale, storage lifecycle policies, shutting down dev at night.
- Medium wins: ARM/Graviton/AMD instances, carbon-aware scheduling, compacting data.
- Report: surface $ + kgCO₂e together so teams see trade-offs.
Edge computing 🌍
- Use cases: personalization, storefront speed, IoT pre-processing, low-latency fraud checks.
- Constraints: tiny runtimes, storage limits, rollout/observability discipline.
- Pattern: “compute where it’s cheap + cache where it’s close.”
Real FinOps levers 💸
- Tag/label everything (owner, env, product).
- Rightsize/turn off: idle VMs, overprovisioned clusters, zombie disks/IPs.
- Commitments: RIs/CUDs/Savings Plans for steady load.
- Storage classes: standard → infrequent → archive, with lifecycle rules.
- K8s cost: workload-level cost via metrics; set team budgets; educate with showback.
Adoption KPIs & OKRs That Matter
Flow & velocity
- Lead time for change, deployment frequency, change fail rate, MTTR.
- OKR example: Reduce idea→production median from 14d to 7d; double weekly deploys per service while keeping CFR ≤ 3%.
Reliability & user experience
- SLO attainment, error budgets, p95 latency, availability by region.
- OKR example: Achieve 99.9% SLO for checkout with ≤ 1% error-budget burn per week.
Security & posture
- Critical misconfig count, MFA coverage, secrets out of code, patch SLAs, time-to-revoke access.
- OKR example: Reduce public-bucket findings to zero; rotate 100% long-lived creds to workload identity.
Cost & efficiency
- Unit economics (cost per request/order/MAU), % tagged spend, commitment coverage, rightsizing savings.
- OKR example: Tag coverage ≥ 95%; realize 20% savings via commitments + rightsizing without SLO regressions.
Platform & data adoption
- Template adoption, time-to-first-merge, data product SLAs, schema contract violations.
- OKR example: 80% of new services from golden templates; cut onboarding to deploy from 10d → 3d.
A 12-Month Cloud Adoption Playbook (Quarter-by-Quarter)
Q1 — Foundations & Guardrails 🏁
- Establish landing zone: accounts/projects, SSO, baseline IAM, hub-and-spoke network, logging, metrics, tracing.
- Ship golden templates (app + API + job), CI/CD skeleton with policy/cost checks.
- Start FinOps: tagging policy, budgets/alerts, first savings scan.
- Pick migration strategy per app (Rehost/Replatform/Refactor) with a scored inventory.
Q2 — First Migrations & IDP v1 🚀
- Migrate a low-risk wave (rehost/replatform) to prove path + playbooks.
- Launch IDP v1: service catalog, starter repos, secrets manager integration.
- Observability standard: enforce traces/metrics in templates; basic SLOs for top 3 services.
- FinOps: kill zombies, downsize test envs, enable storage lifecycle policies.
Q3 — Modernize & Scale ⚙️
- Begin refactor of 1–2 high-impact services (serverless/events or managed K8s).
- Data platform v1 (lakehouse + streaming ingest) for one domain; publish first data product with SLA.
- Security hardening: workload identity, JIT admin, private endpoints, SBOM/signing in CI.
- FinOps: commitments for steady workloads; per-team showback dashboards.
Q4 — Expand, Optimize, Prove Value 📈
- Roll IDP v2 (more templates, cost preview in PRs, platform documentation + office hours).
- Extend SLOs to tier-1 services; run chaos/recovery drills; tighten incident runbooks.
- AI/ML pilot: one inference endpoint with real traffic + autoscale; validate cost/SLA.
- FinOps: quarterly savings review; target unit-cost improvements (e.g., cost per order ↓ 15%).
Executive & Engineer FAQ (Concise Answers)
“Will cloud actually save us money?”
It saves when paired with modernization + FinOps. Expect velocity + resilience first; cost efficiency follows from rightsizing, commitments, and eliminating idle.
“How do we avoid vendor lock-in?”
Use IaC, open data formats, and clean service boundaries. Accept managed services where ROI is clear; abstract only where it’s cheap.
“Do we need multi-cloud?”
Default one primary cloud. Add a second for sovereignty, specialization (e.g., GPU), or negotiation leverage—only if the benefits beat the complexity.
“What about outages?”
Design for multi-AZ, consider cross-region failover for tier-1, and enforce SLOs + drills. Cloud reduces single DC risk; architecture still matters.
“Hybrid forever?”
Many enterprises stay hybrid for years. Treat the data center as another “region” with consistent tooling and gradual attrition of on-prem systems.
“We lack skills.”
Invest in platform engineering, golden paths, enablement, and paired delivery. Make paved roads the fastest way to ship.