Voice isn’t just “speech in, text out.” Good voice apps feel instant, handle noisy rooms, keep state, and do real work. AWS gives you the pieces—Amazon Lex (NLU + built-in speech), Lambda (business logic), Cognito (auth to call AWS safely), and optional Transcribe/Polly when you want custom ASR/TTS.
We’ll first make the landscape crystal clear, then build a real, step-by-step voice assistant that you can run in a browser: speak → intent → Lambda fulfillment → spoken reply. Every code block is separate and explained.
Part 1 — The Building Blocks (clear and practical)
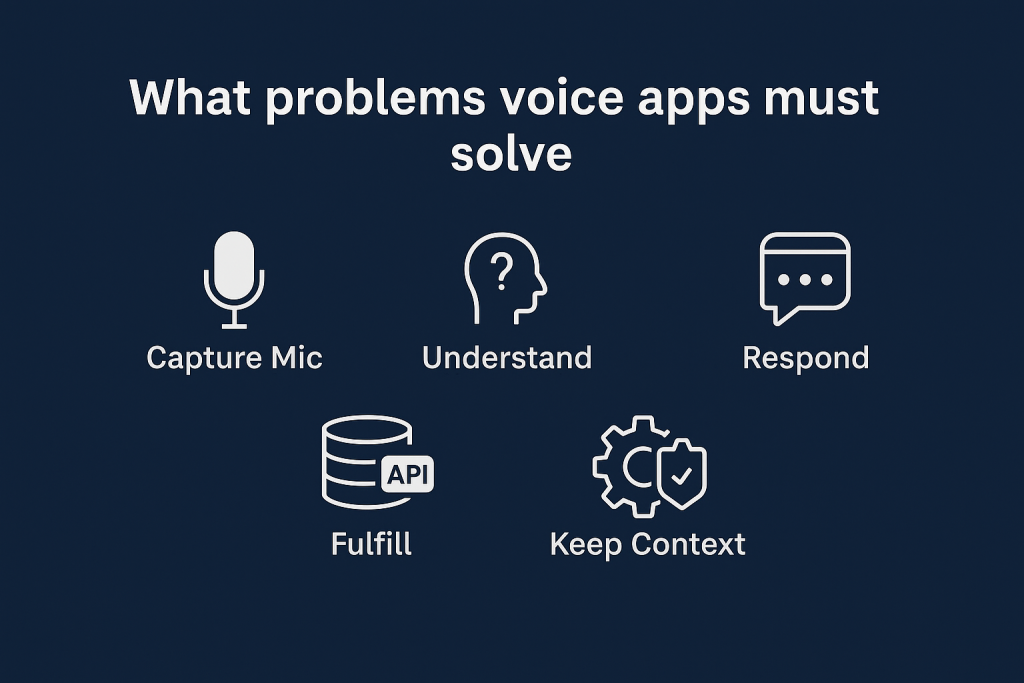
What problems voice apps must solve
- Capture microphone audio and stream it with low overhead.
- Understand the user (intent + slots like
orderId). - Fulfill the request (query a DB, call an API).
- Respond as speech and text.
- Keep context (session state, confirmations, fallbacks).
Two common architectures on AWS
- “Fastest to value” (Lex-centric):
Lex V2 handles speech-to-intent and text-to-speech. You add a Lambda to fulfill. Use this when you want to ship quickly with great accuracy and built-in voices. - “Custom pipeline” (Transcribe + NLU + Polly):
Transcribe for ASR → your NLU (Lex text mode or an LLM) → Lambda → Polly TTS. Use when you need streaming partials, special vocabularies, or custom models.
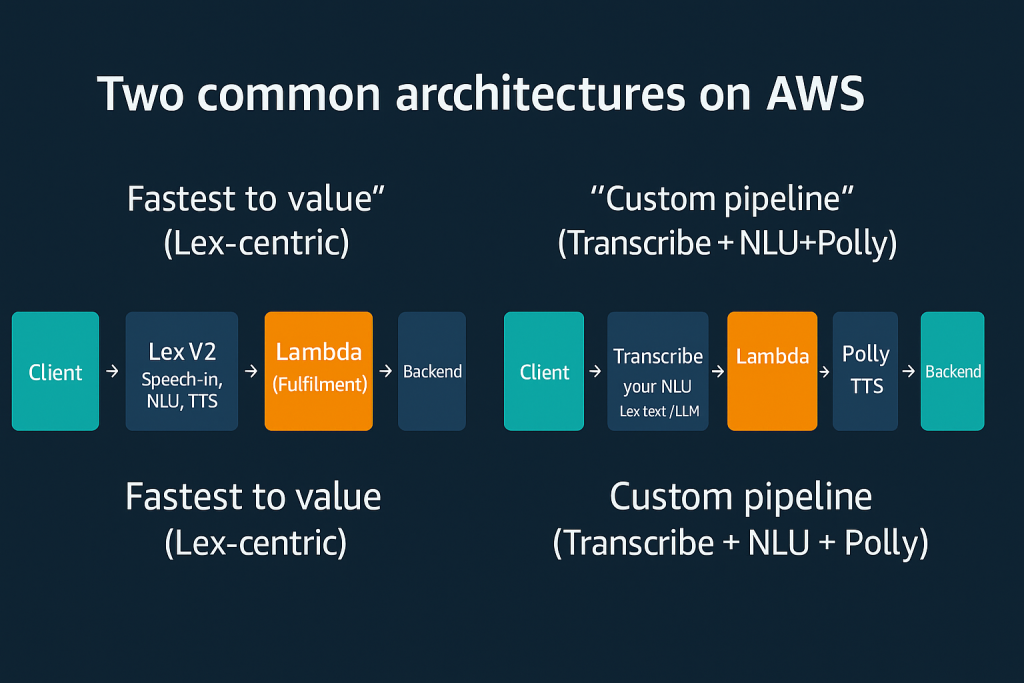
We’ll implement the Lex-centric pattern. It’s simpler: one API (
RecognizeUtterance) gives you intents and a ready-to-play audio reply.
Key AWS services you’ll use (in this example)
- Amazon Lex V2 — intents/slots + built-in ASR/TTS, returns audio replies.
- AWS Lambda — your business logic (fulfillment).
- Amazon Cognito Identity Pool — short-lived credentials for the browser to talk to Lex.
- (Optional later) Amazon DynamoDB (store tickets/orders), Amazon CloudFront (CDN), WAF, etc.
Part 2 — Build a Voice “Helpdesk Assistant” (step-by-step, explained code)
Goal: Users ask “What’s the status of ticket 12345?” Your app understands, runs logic in Lambda, and answers by voice.
What you’ll end up with
- A Lex bot with two intents:
OpenTicketandCheckStatus. - A Lambda fulfillment that returns friendly messages.
- A tiny web page: press 🎤, speak, hear the reply.
Step 0) Prereqs & setup (why this matters)
We give the browser safe, temporary credentials to call Lex. That’s what Cognito does.
- AWS account with admin access to create resources.
- Region (e.g.,
us-east-1). - AWS CLI configured, and Node.js (for the front-end).
Create a Cognito Identity Pool that allows unauthenticated access to Lex (only to your bot). In the console: Cognito → “Federated identities” → Create identity pool → enable unauthenticated identities. Attach an IAM policy like:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": ["lex:RecognizeUtterance"],
"Resource": "arn:aws:lex:REGION:ACCOUNT:bot-alias/BOT_ID/ALIAS_ID"
}]
}Why: The browser signs Lex calls directly; no custom backend needed just to relay audio.
Step 1) Create the Lex bot (what and why)
We define intents, sample utterances, and a slot for ticket numbers. Lex handles speech recognition and intent matching.
In the Lex V2 console:
- Create bot → “HelpdeskAssistant” → English (US).
- Add intent
CheckStatuswith sample utterances, e.g.:- “what’s the status of ticket {ticketId}”
- “check ticket {ticketId}”
Add a slotticketId(Type:AMAZON.Number) → required.
- Add intent
OpenTicketwith utterances:- “open a ticket about {issue}” / slot
issue(free text).
- “open a ticket about {issue}” / slot
- Fulfillment: set Lambda code hook for both intents (we’ll create it next).
- Voice response: in Bot alias settings, pick a Polly voice (e.g., Joanna) so Lex returns audio.
- Build the bot, then Create alias (e.g.,
prod) and test in the console.
Step 2) Write the Lambda fulfillment (plain, explained)
What this does:
Receives the user’s intent + slots from Lex, runs your logic (DB/API), and returns a structured response Lex can speak.
# file: lambda_function.py (Python 3.11 runtime)
import os
import json
from datetime import datetime
def _message(text):
# Lex expects this message shape
return {"contentType": "PlainText", "content": text}
def close(intent_name, fulfillment_state, text, session_attributes=None):
# Tell Lex we're done (Close) with a spoken/text message
return {
"sessionState": {
"sessionAttributes": session_attributes or {},
"dialogAction": {"type": "Close"},
"intent": {"name": intent_name, "state": fulfillment_state}
},
"messages": [_message(text)]
}
def lambda_handler(event, context):
intent = event["sessionState"]["intent"]["name"]
slots = event["sessionState"]["intent"].get("slots", {}) or {}
if intent == "CheckStatus":
# Extract the ticketId slot (value lives under 'value'→'interpretedValue' in Lex V2)
ticket = (slots.get("ticketId") or {}).get("value", {}).get("interpretedValue")
if not ticket:
# Let Lex keep eliciting the slot if it’s missing
return {
"sessionState": {
"dialogAction": {"type": "ElicitSlot", "slotToElicit": "ticketId"},
"intent": event["sessionState"]["intent"]
},
"messages": [_message("Sure—what’s the ticket number?")]
}
# TODO: lookup from DynamoDB or your API; returning a hardcoded response for the example
status = "in progress"
eta = datetime.utcnow().strftime("%b %d %H:%M UTC")
text = f"Ticket {ticket} is {status}. Next update by {eta}."
return close("CheckStatus", "Fulfilled", text)
if intent == "OpenTicket":
issue = (slots.get("issue") or {}).get("value", {}).get("interpretedValue", "your issue")
# TODO: persist to DB and return a real ticketId
ticket_id = "12345"
text = f"Created ticket {ticket_id} for {issue}. I’ll keep you posted."
return close("OpenTicket", "Fulfilled", text)
# Fallback for unknown intents
return close(intent, "Failed", "Sorry, I didn’t catch that. Could you rephrase?")Why this shape: Lex expects sessionState + messages. Using dialogAction: Close tells Lex to speak, then end the turn.
Deploy this Lambda, then in Lex code hooks set it for fulfillment of both intents.
Step 3) Make Lex speak: tiny web client (record, send, play)
What happens:
The browser records short audio (Opus), sends it to Lex’s RecognizeUtterance, then plays back the audio Lex returns (Polly voice you chose).
We use Cognito Identity Pool for credentials and the AWS SDK v3
@aws-sdk/client-lex-runtime-v2.
We keep the sample minimal; you can bundle with Vite/webpack later.
<!-- file: index.html -->
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Voice Helpdesk</title>
<style>
body { font: 16px system-ui; padding: 24px; }
button { font: 16px; padding: 8px 16px; }
#log { margin-top: 12px; white-space: pre-wrap; }
</style>
</head>
<body>
<h3>🎤 Voice Helpdesk (Lex V2)</h3>
<button id="talk">Hold to Talk</button>
<div id="log"></div>
<audio id="replyAudio"></audio>
<script type="module">
import { LexRuntimeV2Client, RecognizeUtteranceCommand } from "https://cdn.skypack.dev/@aws-sdk/client-lex-runtime-v2";
import { fromCognitoIdentityPool } from "https://cdn.skypack.dev/@aws-sdk/credential-providers";
const REGION = "us-east-1"; // your region
const BOT_ID = "YOUR_BOT_ID"; // from Lex V2
const ALIAS_ID = "YOUR_ALIAS_ID"; // e.g., prod
const LOCALE_ID = "en_US";
const ID_POOL_ID = "YOUR_COGNITO_IDENTITY_POOL_ID";
const creds = fromCognitoIdentityPool({
clientConfig: { region: REGION },
identityPoolId: ID_POOL_ID
});
const lex = new LexRuntimeV2Client({ region: REGION, credentials: creds });
const sessionId = "web-" + crypto.randomUUID();
const talkBtn = document.getElementById("talk");
const logDiv = document.getElementById("log");
const audioEl = document.getElementById("replyAudio");
let mediaRecorder, chunks = [];
async function initMic() {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
// Most browsers record Opus; Lex supports Opus in OGG/WEBM containers.
mediaRecorder = new MediaRecorder(stream, { mimeType: "audio/webm;codecs=opus" });
mediaRecorder.ondataavailable = (e) => chunks.push(e.data);
mediaRecorder.onstop = sendToLex;
}
async function sendToLex() {
const blob = new Blob(chunks, { type: "audio/webm;codecs=opus" });
chunks = [];
const arrayBuf = await blob.arrayBuffer();
// RecognizeUtterance uses headers to indicate request/response formats
const cmd = new RecognizeUtteranceCommand({
botId: BOT_ID,
botAliasId: ALIAS_ID,
localeId: LOCALE_ID,
sessionId,
requestContentType: "audio/webm; codecs=opus",
responseContentType: "audio/mpeg", // ask Lex to return MP3 we can play easily
inputStream: arrayBuf
});
const resp = await lex.send(cmd);
// RecognizeUtterance returns metadata in headers. The audio is in resp.audioStream (Uint8Array)
const msg = resp.messages ? new TextDecoder().decode(resp.messages) : "";
const intent = resp.sessionState ? new TextDecoder().decode(resp.sessionState) : "";
logDiv.textContent = `Lex messages: ${msg || "(none)"}\nSession: ${intent || "(n/a)"}`;
if (resp.audioStream) {
const audioBlob = new Blob([resp.audioStream], { type: "audio/mpeg" });
audioEl.src = URL.createObjectURL(audioBlob);
await audioEl.play();
}
}
talkBtn.addEventListener("mousedown", async () => {
if (!mediaRecorder) await initMic();
logDiv.textContent = "Listening… release to send";
chunks = [];
mediaRecorder.start();
});
talkBtn.addEventListener("mouseup", () => {
if (mediaRecorder && mediaRecorder.state === "recording") {
mediaRecorder.stop();
logDiv.textContent = "Processing…";
}
});
</script>
</body>
</html>Why these choices
- Opus/WebM is what browsers naturally record; Lex V2 accepts it and returns MP3 we can play easily.
- We use Cognito so the browser can call Lex directly, without storing any AWS keys.
- We show Lex’s messages and session state so you can debug what the bot understood.
If your browser only records OGG Opus, set
requestContentType: "audio/ogg; codecs=opus"and record with"audio/ogg;codecs=opus".
Step 4) Test the round-trip (and what “good” looks like)
- Open
index.htmlin a simple static server (e.g., VS Code Live Server). - Press and hold Hold to Talk, say: “What’s the status of ticket one two three four five?”
- You should see Lex messages in the log and hear the voice reply.
- In the Lambda logs (CloudWatch), you’ll see each invocation with the parsed slots.
If it fails:
- 4xx from Lex usually means IAM (Cognito role missing
lex:RecognizeUtterance) or bad bot/alias IDs. - No audio? Check browser microphone permissions and verify
responseContentTypeisaudio/mpeg.
Extensions & Options (when you go beyond MVP)
Better fulfillment (store real data)
Swap the hardcoded status for a DynamoDB lookup:
# inside CheckStatus branch
import boto3
ddb = boto3.resource("dynamodb")
table = ddb.Table(os.environ["TABLE_NAME"])
item = table.get_item(Key={"pk": f"TICKET#{ticket}" }).get("Item")
status = item["status"] if item else "not found"Interruptible speech & partials
Need interruption or live captions? Use Lex Streaming or go “custom pipeline”:
Transcribe Streaming (ASR partials) → Lex (text mode) or an LLM → Lambda → Polly for TTS.
Mobile apps
Use Amplify (Auth + Storage + API) or call Lex directly with the AWS SDK on iOS/Android. The architecture stays the same.
Telephony
Amazon Connect can front phone calls, invoke your Lex bot for IVR, and route to agents—no web client needed.
Troubleshooting (fast fixes with context)
- Lex understood the wrong thing: Add more sample utterances; set slot prompts/confirmations; tune the slot type (e.g.,
AMAZON.Number). - Cognito returns “not authorized”: Confirm the unauthenticated role has
lex:RecognizeUtteranceon your bot alias ARN, and the identity pool ID matches. - No audio playback: Ensure bot alias has a Polly voice configured; keep
responseContentType = audio/mpeg; check browser autoplay policies (user gesture required). - Lambda timeouts: Keep fulfillment snappy (200–800 ms). For long tasks, confirm with the user and asynch the heavy work.