Part 1 — Concepts You’ll Use Every Day
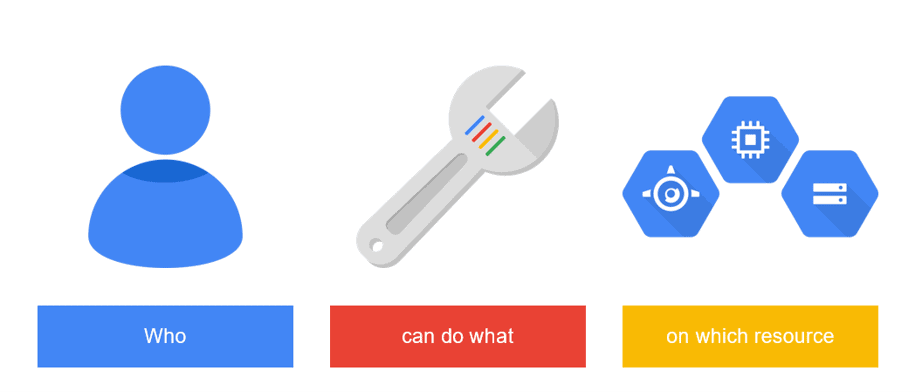
The model in one line 🔐
IAM decides who (principal) can do what (permissions through roles) on which resource (scope), sometimes under which conditions (time, path, attributes). Every decision maps back to those four words.
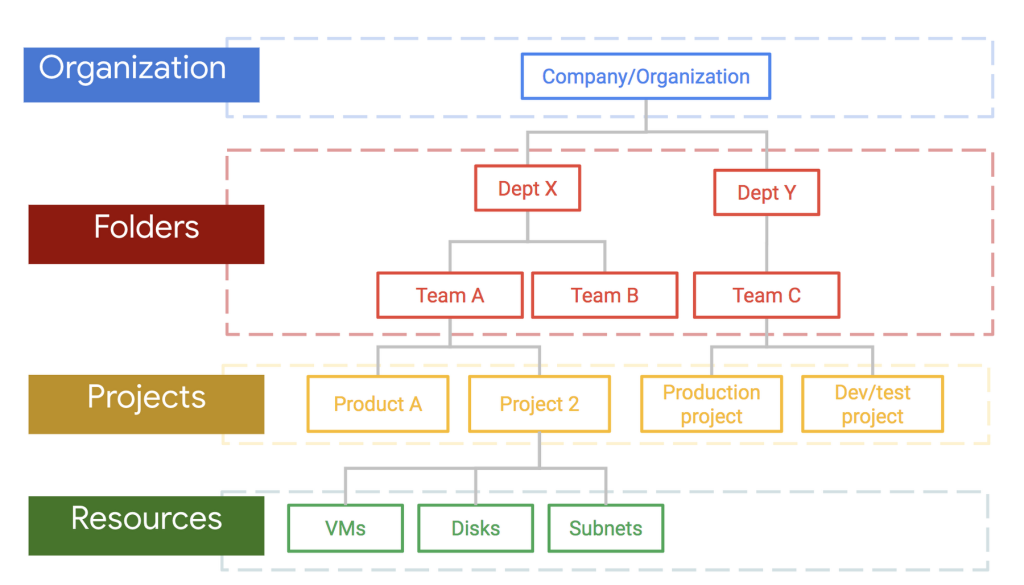
The map: Organization → Folders → Projects → Resources
Policies live on this hierarchy and inherit downward.
- Organization: truly global readers (e.g., auditors).
- Folders: domain/platform teams.
- Projects: app or environment (dev/stage/prod) access.
- Resources: a specific bucket, dataset, or service when precision matters.
Rule: grant at the lowest sensible scope so inheritance doesn’t surprise you.
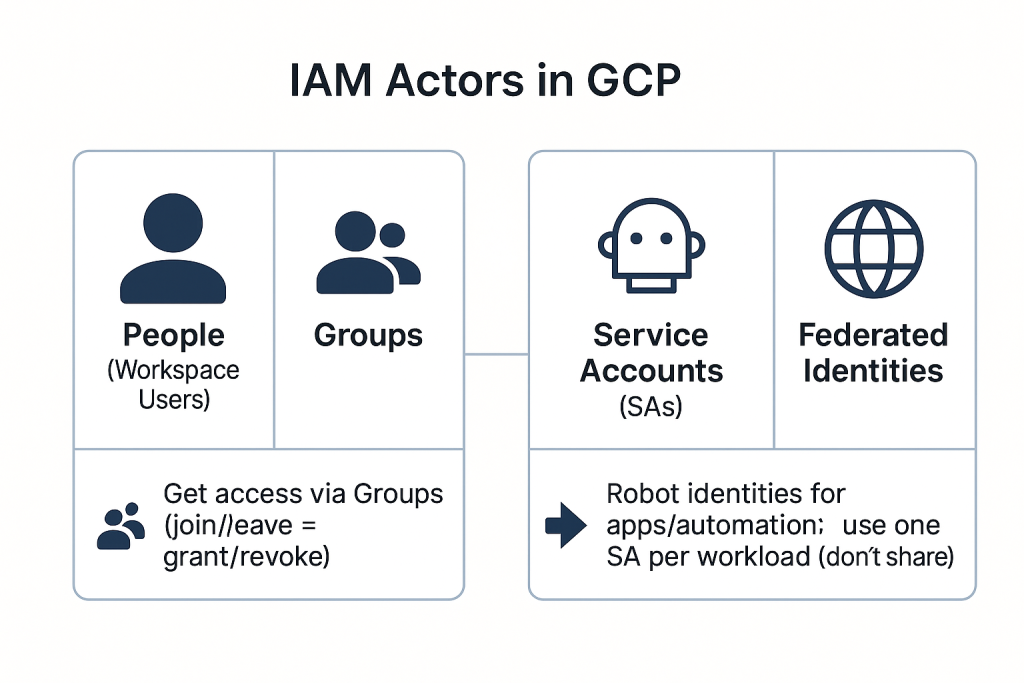
The actors: People, Groups, Service Accounts 🧩
- People (Workspace users) get access via Groups (join/leave = grant/revoke).
- Service Accounts (SAs) are robot identities for apps/automation; use one SA per workload (don’t share).
- Federated identities (e.g., GitHub Actions) receive short-lived access—no static keys.
This separation makes audits clear and blast radius small.
The verbs: Roles (avoid “Editor”)
- Basic roles (
Viewer/Editor/Owner) are coarse; avoidEditor/Ownerin prod. - Predefined roles (e.g.,
roles/storage.objectViewer,roles/run.invoker) are task-sized—prefer these. - Custom roles only when predefined is too broad/narrow.
Think in read / write / admin; give the smallest role that lets the job succeed.
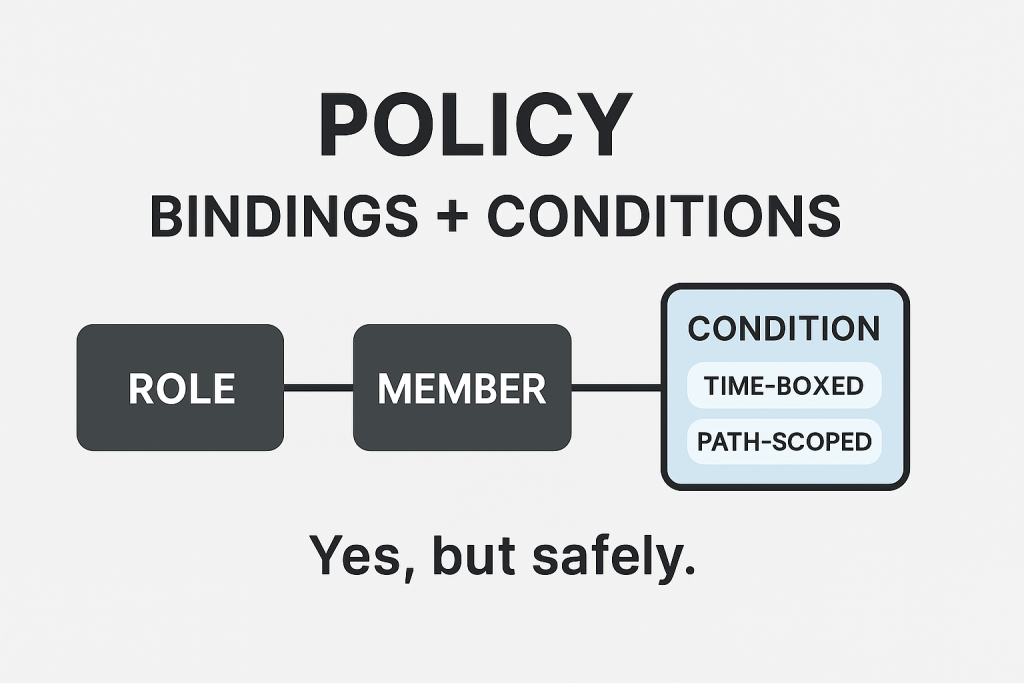
The rules: Policies & Conditions (precision without drama) ⚖️
A policy is bindings of role ↔ members, optionally with a Condition (CEL), like:
- Time-boxed: “Read until Friday.”
- Path-scoped: “Write only under
gs://shared/appA/.”
Conditions let you say “yes, but safely” for vendors, incidents, and shared buckets.
Organizing for flow (environments, personas, apps) 🚀
- Separate projects for dev/stage/prod; it simplifies IAM, logs, and billing.
- Map humans to groups (Readers, Developers, Operators, Security).
- Run every service as its own SA; grant minimal roles on exact resources (bucket/dataset/topic).
With that, onboarding/offboarding and incident access become routine instead of risky.

Part 2 — Implementation You Can Ship
Inspect & grant (baseline you’ll run first)
# Who has what on a project (human-readable)
gcloud projects get-iam-policy $PROJECT_ID --format=yaml
# Group gets object-read across the project (broad but safe)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member=group:analytics@company.com --role=roles/storage.objectViewer
# A service account gets write-only on one bucket (tight and precise)
gcloud storage buckets add-iam-policy-binding gs://shared-data \
--member=serviceAccount:etl@${PROJECT_ID}.iam.gserviceaccount.com \
--role=roles/storage.objectCreatorTwo Conditions that solve 80% of real cases
Time-boxed access (incident/support window)
condition:
title: "IncidentWindow"
expression: request.time < timestamp("2025-09-02T00:00:00Z")Prefix-scoped writes in a shared bucket
condition:
title: "OnlyAppPrefix"
expression: resource.name.startsWith(
"projects/_/buckets/shared-data/objects/appA/"
)Keyless workloads (Cloud Run & GKE)
Cloud Run → run as a minimal SA; callers need run.invoker + ID token
gcloud run deploy api --image=us-docker.pkg.dev/$PROJECT/app/api:latest \
--region=us-central1 \
--service-account=api-sa@$PROJECT.iam.gserviceaccount.com
gcloud run services add-iam-policy-binding api \
--member=serviceAccount:frontend-sa@$PROJECT.iam.gserviceaccount.com \
--role=roles/run.invoker --region=us-central1GKE Workload Identity → map KSA→GSA; no JSON keys
apiVersion: v1
kind: ServiceAccount
metadata:
name: invoices-ksa
namespace: invoices
annotations:
iam.gke.io/gcp-service-account: invoices-gsa@PROJECT.iam.gserviceaccount.comgcloud iam service-accounts add-iam-policy-binding \
invoices-gsa@${PROJECT}.iam.gserviceaccount.com \
--member="serviceAccount:${PROJECT}.svc.id.goog[invoices/invoices-ksa]" \
--role="roles/iam.workloadIdentityUser"CI/CD without secrets (Federation + Impersonation) 🔑
- Create a Workload Identity Pool + OIDC provider for GitHub.
- Bind your deployer SA with
roles/iam.workloadIdentityUserto the repo/branch attributes. - In CI, exchange OIDC → short-lived creds → impersonate the deployer SA.
Result: no JSON keys in repos; deploys are auditable and scoped.
Cross-project access (choose one)
- Grant on the target: give App A’s SA roles on Bucket B (explicit, simple).
- Impersonate a target SA: allow App A to become
writer@projectB; that SA holds the bucket roles (centralized power & auditing).
Guardrails you’ll turn on
- Organization Policies for posture:
- Disable SA keys:
constraints/iam.disableServiceAccountKeyCreation - Restrict member domains & regions
- Disable SA keys:
- IAM Deny (sparingly) for destructive APIs where an explicit “no” must override every “yes”.
A 60-day rollout that keeps momentum
- Days 1–10: Inventory projects/groups/apps; plan to remove
Editor/Owner. - Days 11–20: Move humans to groups; enforce no SA keys org-wide.
- Days 21–30: One SA per workload; minimal predefined roles on exact resources; stop using default SAs.
- Days 31–40: Make workloads keyless (Run SA, GKE Workload Identity); set up CI federation + impersonation.
- Days 41–50: Add time-boxed and prefix-scoped Conditions; delete broad grants.
- Days 51–60: Enable Audit Logs (Data Access where needed), save Asset Inventory queries, schedule a quarterly review.
Quick checklist (copy into your runbook) ✅
Audit logs to BigQuery; run Recommender quarterly.
Humans via Groups; zero direct user bindings in prod.
One SA per workload, documented owner.
No static keys (attached identity or federation + impersonation).
Separate dev/stage/prod projects.
Replace Editor/Owner with predefined/custom roles + Conditions.